
金融领域的纵向联邦学习探索
Published:
依据联邦学习的不同参与方持有数据的特点不同,可以将其分类为横向联邦学习、纵向联邦学习以及联邦迁移学习等。
横向联邦学习是样本的分割,由于其良好的特性可以设计出较为通用的联邦学习方案。而更为困难且在业界得到很多应用的是纵向联邦学习,其特点是不同数据持有方具备的是同一样本(往往是某个客户)的不同特征维度,这是由于不同的公司业务不同造成的。
在风控场景中纵向联邦学习得到了更为广泛的应用与发展,其特点是,标签仅为其中一方所持有(以下称为Guest方),而其他各方拥有数据的部分特征(以下称为Host方)。Guest方希望通过与Host方的合作来提升模型的效果,达到降低风险的目的。在此过程中,Guest方和Host方均需要保证己方的数据安全性。
SecureBoost
在风控场景中,树模型由于其具备良好的可解释性和强大的学习能力被广泛应用。以XGBoost为代表的递归联邦学习模型非常火热,其原理是通过M步的boosting构建M个子模型$f_1$,…,$f_M$, 这M个子模型的构建是使用逐步提升的方法,在第m步时,$f_1$,…,$f_{m-1}$这m-1个子模型已经建立,$f_m$的建立目标是最小化损失函数:
\(obj^{(m)}= \sum_{i=1}^n Loss(y_i,\hat{y}_i^{(m-1)}+f_m(x_i))+\Omega(f_m)+constant\),
其中$\hat{y}i^{(m-1)}=\sum{j=1}^{m-1}f_j(x_i)$ 为前面已经构建的由m-1个随机森林组成的模型的输出,$\hat{y}i^{(m-1)}$为向量$\hat{y}^{(m-1)}$的第i个值,${x_i:i=1,…,n}$为训练数据集,$Loss(y_i,\hat{y}_i)$为损失函数,如均方误差(MSE)损失函数为$Loss{MSE} (y_i,\hat{y}_i)=1/2(y_i-\hat{y}_i)^2$。 将XGBoost扩展到纵向联邦场景下,为了保护数据的隐私与安全,SecureBoost方法被提出,提供了一种安全地构建梯度提升树模型的思路。它包含了两个过程,首先对样本进行加密对齐,其次进行加密的模型训练,一个典型的纵向联邦梯度提升决策树模型建模流程如图所示:
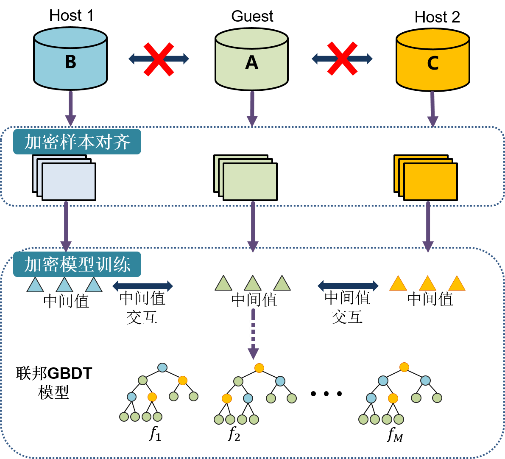
第一阶段 加密样本对齐 由于训练算法需要各参与方将属于同一条数据的特征对应起来,为了保护数据隐私与安全,框架基于隐私求交技术将数据样本对齐。
第二阶段 加密模型训练 在第二阶段,基于对齐后的数据利用各参与方的数据进行联邦建模。中间数据通过同态加密算法(如Pailllier)来保护中间值的安全性,防止泄露数据隐私。建立梯度提升树模型的关键在于
- 第t棵树的构建是以第t-1次的标签残差为目标进行学习的;
- 每棵树的构建中,决定每个节点如何分裂、是否分裂,这一过程是由多方合作、信息交换计算出每个特征在每个阈值分裂后的得分,取最大得分的结果进行分裂来实现的。
Guest方算出对于每个m-1次迭代后的预测值$\hat{y}^{(m-1)}$(初始为0)的一阶导数$g_i$和二阶导数$h_i$,对$g$和$h$进行同态加密后传输给每一个Host方。Host利用公钥计算出每个特征每个分裂的一阶导数求和和二阶导数求和并发送给Guest方解密;Guest则直接计算每个特征每个分裂梯度聚合值明文。
Guest方根据得到的所有的一阶导数和二阶导数聚合值算出每个特征每种分裂的得分,如果最大得分小于阈值$\gamma$则不分裂。否则按照相应属性和阈值分裂当前节点,得到对应的两个叶子节点和各自的样本id集合$I_L$和$I_R$。对于第m棵树的每一个叶子节点,循环执行以上,直到所有的叶子节点不能再分裂或者树的深度达到设置的最大深度为止,Guest方计算出每个叶子节点的最优权重$w_i$,则第m棵树构建完成。
由此联邦学习过程可知,在建模过程中,Guest方和Host方无法获知对方的数据信息,保证了各参与方的数据安全。同时,每棵树的每个节点构建过程,Guest与Host需要通过大量的加密文通讯找到最优分裂特征信息,大大增加联邦模型的通讯成本。
可解释性要求
下面以单方子模型场景为例,讨论下联邦学习模型对可解释的要求。
单方子模型是在联邦学习场景中应用广泛的一种场景。单方子模型考虑的是双方进行联合建模,其中一方仅有数据样本标签,一方拥有数据样本特征的新场景。其中Guest方即业务方只拥有数据标签,并希望借助其他组织机构的数据进行联合建模,因此通常为联邦学习的主动方;借助给Guest方数据的组织机构即为Host方,通常为联邦学习的被动方。
相比于现有技术应用场景,单方子模型场景对实现联合构建联邦XBG模型的可解释性提出了新的要求,主要表现在Guest方需要了解模型节点的特征含义,以达到模型对结果的可解释性要求。 基于对节点特征含义的要求,产生如下两个进一步需求:
- 为了保护Host方数据隐私,Guest方不能获取具体样本对应的预测值$\hat{y}$。为了获得可解释性,Guest方需要获取模型节点的特征含义。此时若Guest方得到了样本预测值$\hat{y}$则Guest方同时也会得到该样本在模型中的预测路径,这将暴露每个样本的特征信息,进而推测出Host方的样本隐私信息。
- 为了保护Guest方数据隐私,Host方不可获取Guest方的隐私数据即样本标签以及模型的叶子节点权重信息,因为模型叶子节点权重中包含Guest方的样本标签数据信息。
然而现有方案无法在单方子模型场景下同时满足上述两个要求:
- SecureBoost方案中虽然保证了Guest方保有模型权重参数,但仍需要Guest方得到单个样本预测值以进行信息增益的计算。在Guest方得知整个模型的分裂特征情况下,这种行为会使得Guest方通过单个样本预测值回推出Host方的样本数据,进而无法保证双方的数据隐私,限制了联邦学习的应用场景。
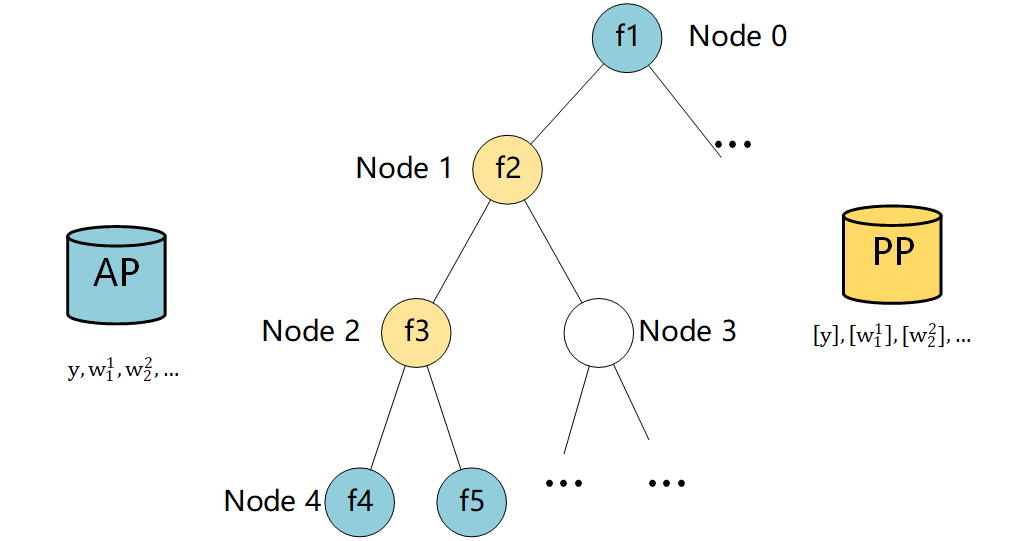
- 具体举例如下图所示,Guest方得知$S_i$的预测结果,可知样本的预测结果与叶子节点Node4的权重值一致,则判断样本$S_i$属于叶子节点Node4。进而可知$S_i$属于Node1和Node2。例如Node2处的特征含义为“是否存在过违约行为”,根据大多数样本“不存在违约行为”的不均衡分布可以推测出$S_i$的特征含义。类似的,可以泄露大量Host方数据特征内容。
效率与有效性
目前基于同态计算的联邦学习方法需要在Guest与Host之间传递大量加密数据,每轮训练中都需要传递大量的同态密文,造成通讯成本巨大。目前的SecureBoost方法虽然可以提供更高的安全方案,保护Guest的标签和Host的特征信息,但是付出了巨大的通讯成本,大大降低了模型的可用性,也成为基于同态加密的联邦学习方法实际落地的困难。
SecureBoost的每轮的训练过程中Guest都需要计算节点样本的一阶、二阶梯度,并传递一阶、二阶梯度给所有Host,所有Host特征的分裂都需要将计算的梯度聚合值发回给Guest解密,得出最优分裂;由于在密文上进行运算,加上传递通讯数据很大,传输时间久。随着训练模型的棵树增多,训练成本大幅增加。